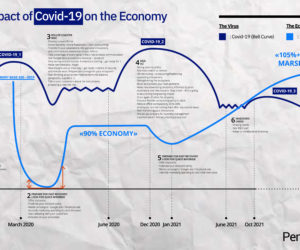
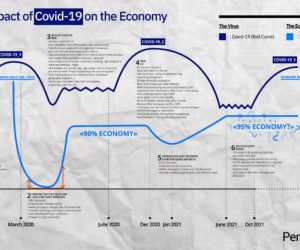
With public health restrictions returning as the cold weather sets in, we see 6 key drivers of technology resilience that CTOs, CIOs and even CEOs need to remain focused on as COVID-19 continues to unfold.

Pentalog is here to help in these troubled times, so we’re offering our IT outsourcing services to new customers.
The tech story of the pandemic has been rapid adaptation – businesses innovating for survival and growth, strengthening and re-imagining technical capabilities to deploy and manage remote workers and to service homebound customers in often radically new ways.
We surveyed these dynamics over the summer to see how companies had begun to respond by focusing on priorities such as automation, security and cost control to keep business nimble and customer-centric.
Against the backdrop of what public health experts have warned will be a difficult winter, we believe that technology leaders will continue to need to play the role of resilience change agents within their organizations.
Below we offer 6 key insights to help tech leaders stay ahead of the curve.
1. Agile Security Strategy
Unavoidable disruptions such as switching to remote work during the COVID-19 pandemic have caused new types of security challenges, such as employees using personal computers or providing access to secure networks from home. At Pentalog, we shifted more than 1,100 employees to a remote environment in a matter of a few days, while maintaining team commitment and productivity to our clients.
Security strategy requires adaptability. Not only as new threats arise regularly, but also as technical and team environments continuously evolve. As a matter of fact, the number of threats is reported to have increased exponentially.
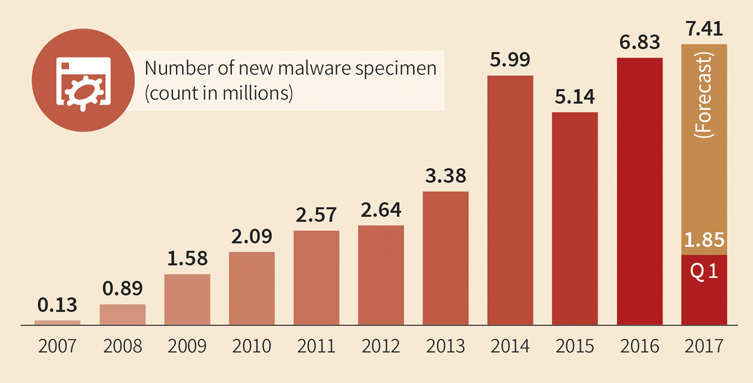
Source: https://www.gdatasoftware.com/blog/2017/04/29666-malware-trends-2017
Today, the most popular approach is DevSecOps, which includes security within agile DevOps practice, that is to say, as part of the development process. Security becomes a shared responsibility and no longer belongs to a specific siloed specialty.
In parallel, automation enforces the testing, validation, and recovery processes. DevSecOps requires an investment, but getting there hardens a platform’s ability to resist breaches.
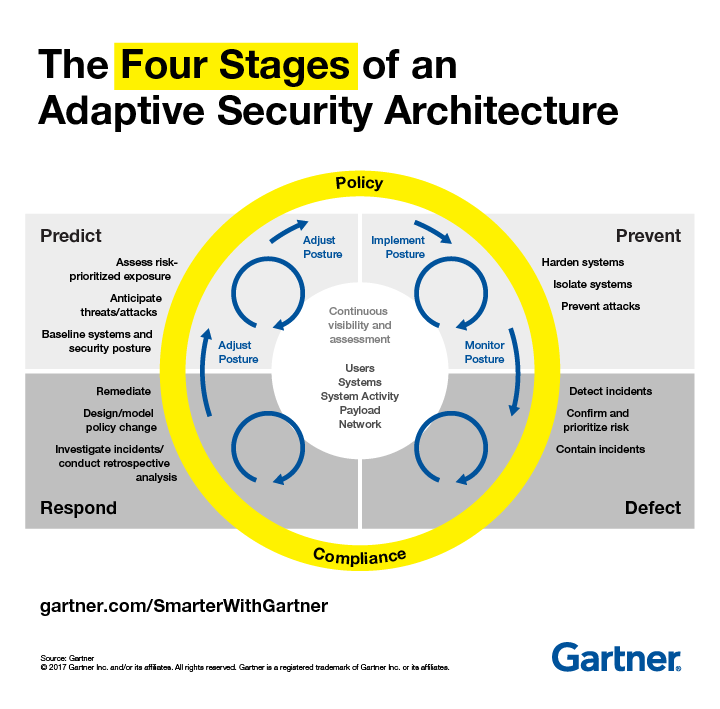
Other agile approaches to security should also be considered. Gartner has collected and named such practices under the name of Adaptive Security Architecture in its 2017 tech trends or Cybersecurity Meshes in the 2021 tech trends. The core concept is that security breaches are unpredictable. So, rather than having an “incident response approach, it is safer to run a “continuous response” stance and always be in the mindset of responding to an event.
Furthermore, Cybersecurity Meshes acknowledge the distributed architecture trend which was accelerated with COVID-19 and the move to remote work. It promotes securing and facilitating access to assets wherever they or the people are located.
2. Increased Performance Visibility
In times of crisis, you can expect changes to many aspects of technical products. For example, an increase in traffic can necessitate changes to infrastructure; teams may lose momentum; users might behave differently and expect new types of features.
To continuously anticipate and adapt, it is critical to understand a project’s underlying trends. Measurement and telemetry are the core practices to implement and constantly improve.
They should cover as many fields as possible:
- Team performance (momentum, mood, obstacles)
- Product technical performances (resource consumption, response time, databases)
- Security (access logs, abnormal queries)
- Analytics (user profiles, user behavior)
Telemetry requires more than tools and technologies (such as Centralized Log Management or Predictive Monitoring) but also a cultural shift. Team members must share responsibility to suggest, implement, validate and monitor project activities.
For example, every feature on a backlog should outline in its Definition of Done the criteria to measure its success, failure, or related risks. The process and organization to track these metrics should also be clear: who should review what, when, and how. Furthermore, any governance should regularly reassess the quality and coverage of its measurements.
It may be counterproductive to aim too high too fast. Define short and long-term objectives, then on a roadmap, clearly list small steps to accomplish each of those objectives. Regularly assess progress and refine goals from lessons learned, new technologies, or capacities.
Artifacts such as Maturity Models can be an excellent basis to provide transversal visibility to provide awareness, motivation, and transparency to each person on the project.
3. Automation to Mitigate System Failures
Just think about it: Netflix requires very few people behind the scenes to support its infrastructure in case of failure. Thanks to automated systems, the content provider can self-react and mitigate most shortcuts.
Netflix is ready for failure, embracing Amazon CTO Werner Vogel’s famous quote: “Everything fails all the time.” This means you should orient your effort to expecting failure and reacting before it occurs.
For instance, when authentication down, Netflix provides access for free, rather than shutting down the platform. They even have a practice they call ‘chaos engineering’ which pressure tests production applications by constantly triggering breakdowns.
We should all learn from this example and promote automation within fault-tolerant systems to take over in times of crisis. It’s not only a matter of reliability. Other benefits of automation are cost reduction, productivity, availability and performance.
In the case of a pandemic like the coronavirus outbreak, when people get sick, automation processes show their priceless value when systems crash, and there’s no one on-site to fix them. A positive DevOps philosophy should promote frequent releases, high automation and software reliability.
Today, a wide range of technological tooling is largely accessible and easy to implement – solutions that increase the automated resilience of technical products: Cloud Platforms provide one-click self-healing options. You can quickly set up software such as Chaos Monkey to assess the service’s response to failure and more.
Furthermore, it’s advisable to share a high-level understanding of the DevOps culture among your larger business team to promote the importance of stability and upgradability of applications. Doing so can help align development and operations environments around your business goals, as they evolve to confront change.
4. Automation to Ensure Scalable Systems
Overconsumption of resources can also cause system disruption and failure, as noted. One example everyone can relate to is spiking demand for communication and collaboration services for businesses, medicine, schools and social life.
Since so many people started working from home at the same time, companies had to adopt enterprise mobility tools and services, and many internet-based solutions burst beyond their limits. Tools such as Microsoft Teams and Zoom are ubiquitous now report hundreds of millions of daily active users.
With traditional on-premise-based IT, adapting infrastructure to consumption needs takes days or weeks. We faced projects where it even took months to acquire a new machine, from commercial negotiations until finalizing the server setup, which is obviously a huge risk.
In most cases, if infrastructure is under-scaled for peak times, the process of adapting infrastructure might slow down or even crash the product. If it’s over-scaled the rest of the time, that’s a waste of money, which companies often cannot afford during a crisis.
Fortunately, an increasing number of Cloud and SaaS platforms offer services that accommodate real-time resource needs with a “pay as you go” model. During peak times, infrastructure scales up to ensure a continuous flawless experience for the end-users, or it scales down to optimize costs.
For any business still hesitating, now is the time to move to a cloud platform and leverage expenses and capacities to your business to deliver a scalable infrastructure.
5. Management to Control IT Costs: FinOps
Managing costs is not just about the tools you choose to enable. For instance, when we mention infrastructure, it’s not as simple as auto-scaling, which can also create waste if not set up properly.
The fact is that cloud platforms that support such technologies have grown in complexity. To address these changes, specific practices and roles such as FinOps have risen. FinOps leverages cost optimization as a specific activity with a clear focus that dictates the project’s organization and governance.
If FinOps focuses on Cloud Platforms expenses, you could also apply the methodology and focus to other sources of expenses. More knowledge, control, and adaptation of expenses surely enhance the chances of companies to adapt during a crisis.
Flexibility and resilience will always be key in times of disaster. Now more than ever, it’s critical to build these qualities into your technology cost management processes.

CTO challenges 2020: Use cost control and project management tools to improve project performance.
6. Low Code to Deliver Apps Faster than Ever
Finally, we add to the list low code, a set of technologies that have really gotten a lot of attention recently for companies seeking to radically trim cycle times for new applications for internal company users.
That is to say, if the crisis period has been one where the capacity for rapid business innovation has been decisive for survival and growth, low code has emerged to show how business owners can lead “development projects” with and without tech support faster than ever.
For example, since the start of the pandemic, Pentalog created for its own use more than 20 apps in Microsoft Power Apps. These apps have covered purposes such as simplifying project staffing to organizing WFH, adding transparency to our service catalog and improving our search tools.
With low-code, stakeholders save time by drawing on a wide selection of design libraries and switching to hand-coding only when needed. This allows them to iterate like never before to launch products and services that integrate with legacy systems in weeks, collect user feedback and make updates in minutes.
To emerge from COVID strong and even stronger than before, the power of low code to accelerate digital transformation should not be ignored.
Also read: