

Let’s say we visit a bookstore’s website to look for specific products. We might consider filtering the books by certain criteria, such as genre, author, price, or words in the description. All of these filters added to the search field make the users’ journey easier.

Product filtering is a tricky topic in any eCommerce application. For this purpose, Elasticsearch is often the right answer.
Elasticsearch provides these features and many more. You can display the highest-rated products at the top of the result list and see relevant results even if you make a small typo.
If you want to find out what Elasticsearch is and how you can use it, keep reading.
What is Elasticsearch?
Elasticsearch is a powerful analytics and full text search engine that stores data in JSON format. It’s open-source, developed in Java, on top of Apache Lucene.
Widely used for building complex and performant search functionalities, Elasticsearch has many popular clients worldwide, including Netflix, Facebook, and Adobe.
Why Use Elasticsearch?
First and foremost, Elasticsearch is excellent at doing what traditional databases can’t do: full text search. Both relational and non-relational databases are very slow when it comes to this search technique.
A full text search is capable of returning documents that don’t completely match the search criteria. For example, if we searched for “mathematics” and “informatics” in a description, an application backed up by full text search will also be able to return results that contain only one of those words, or slightly modified versions. It is also preferable to return the most relevant results first.
While this is theoretically possible in a relational database using the LIKE operator, the reality is that such a query would be extremely slow for a large dataset.
If we also added a simple AND/OR condition next to a LIKE, the performance would decrease even more. Also, there would be no way to handle typos or retrieve the most relevant results first.
Elasticsearch, on the other hand, can handle typos very easily and knows all about relevance. It also allows us to write complex queries using its REST API.
Besides, Elasticsearch is fast, distributed, scales extremely well, and has failover mechanisms in place to avoid data loss.
How Does Elasticsearch Mapping Work?
Whenever we load a document into Elasticsearch, a process called dynamic mapping steps in. Dynamic mapping is Elasticsearch’s method of determining the type of data that we load into it.
It can recognize dates by format, numbers, and strings. If dynamic mapping is not enough for our needs, explicit mapping can be defined as well.
Basic Concepts of Elasticsearch
Index, node, and cluster are the basic concepts of Elasticsearch.
An index is a collection of documents with similar characteristics. As a concept, you can compare it to a relational database. For example, we can have an index for customer data and another one for product information.
A node is a running instance of Elasticsearch on a physical or virtual machine. A node can be configured to join a specific cluster or form one on its own.
A cluster is a collection of related nodes that, together, contain all of the data from an index.
So, now that we know the basics of the Elasticsearch’s architecture, let’s look at the great features it offers, starting with scalability.
Why Does Elasticsearch Scale So Well?
Elasticsearch is distributed by nature, built to always scale with your needs.
Let’s say we have an index of 600 GB and a single node with a capacity of 500 GB. We clearly cannot store the entire index there. However, we have the option of adding another node, so that Elasticsearch can store data on both nodes.
To do this, Elasticsearch uses sharding, a mechanism to separate the index in multiple pieces. This is how Elasticsearch horizontally scales the data. Note that an index contains a single shard by default, but we can configure the number of shards.
Elasticsearch can scale up to thousands of servers and accommodate petabytes of data. Its enormous capacity results from its elaborate, distributed architecture. However, things can still go wrong from time to time. So, how does Elasticsearch handle those cases?
What About Failover Mechanisms?
What if we had a single node and it failed? We clearly don’t want to lose all of our data.
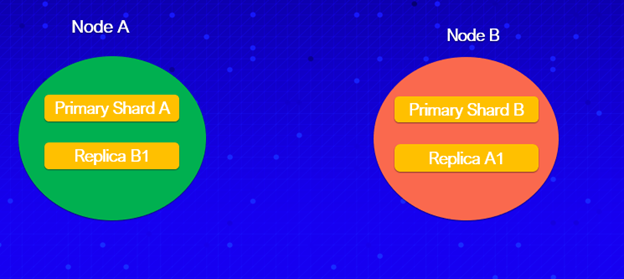
Fortunately, there’s a mechanism in place called replication, which is enabled by default. It’s configured at index level and it creates copies of shards, referred to as replica shards.
Replicated shards are called primary shards. Replica shards can serve search requests just like a primary shard. So, if something happens and a replica shard handles your search request, Elasticsearch takes care of everything behind the scenes and there’s no impact to the end-user.
Similar to sharding, the number of replicas is configurable. Elasticsearch places replica shards on a different node than the primary shard they belong to, which is why we need a minimum of two nodes to use replication.
How Can I Configure the Number of Replicas?
It depends! Why? We should consider the use case, resources, data, and many other factors. However, guidelines come in handy.
First, decide how critical the data is. If it’s really important, we clearly need to increase the number of replicas.
Second, ask yourself: can I restore the data from other sources? And if so, is downtime acceptable while re-indexing the data?
The answers to these questions will help you to decide on how many replicas to add.
Analysis Process
When you load a document into Elasticsearch, its text fields go through an analysis process. An analyzer is composed of character filters, tokenizers, and token filters.
The standard analyzer does not perform character filtering. It uses a tokenizer that splits by whitespace, removes common symbols such as punctuation marks, and uses a token filter that lowercases the words.
Note that we can use a custom analyzer fully adapted to our needs, but in most cases, the standard analyzer is enough. Once the analyzer finishes this process, the result is stored in something called the inverted index. This structure represents a mapping between the terms and which documents contain those terms.
By looking in the inverted index instead of the JSON documents, Elasticsearch manages to perform a fast-full text search.

A full house at the PentaBAR event where I introduced people to the amazing world of Elasticsearch.
So, What’s So Great About Elasticsearch?
Well, that’s a long list. Elasticsearch allows us to store and search large volumes of data very quickly. It can also handle typos and we can easily write complex queries to search by any criteria we want. It also allows us to aggregate data to obtain statistics. It scales data horizontally, has a failover mechanism in place, and can do so much more! Elasticsearch can provide search-as-you-type functionality and use machine learning to detect anomalies in the data and make predictions.
I hope I’ve convinced you to give Elasticsearch a try if you haven’t already.
Elasticsearch serves so many enterprise use cases and I think there’s definitely a good chance that it will serve yours, too!









Dan Pop
February 13, 2020 at 10:52 am ESTBuna! Aici ai vrut sa scrii “NEST API” sau “REST API” ? 🙂
“It also allows us to write complex queries using its REST API”
Merci,
Dan
Stefana Paraschiv
February 13, 2020 at 12:11 pm ESTBuna,
E vorba despre REST (representational state transfer). Elasticsearch ofera posibilitatea de a vizualiza sau manipula datele din index prin requesturi HTTP de tip GET, PUT, POST sau DELETE. Recomand sa arunci un ochi pe documentatia lor daca esti curios, punand accent pe Index APIs, Search APIs si Document APIs. Mie mi-a fost foarte utila. https://www.elastic.co/guide/en/elasticsearch/reference/current/rest-apis.html
Mersi,
Stefana