
Have you ever had performance issues with MongoDB? Did you find a quick and universal solution to boost your database server?
Regardless of whether you answered yes or no, this article is for you.
After working with MongoDB for over 7 years, I’ve compiled a list of 7 angles from which to approach a performance issue with your MongoDB application.
Mastering MongoDB
#Tip 1: Boost your Hardware
According to Von Neumann architecture, there are 3 main components that are key elements of a performance server.
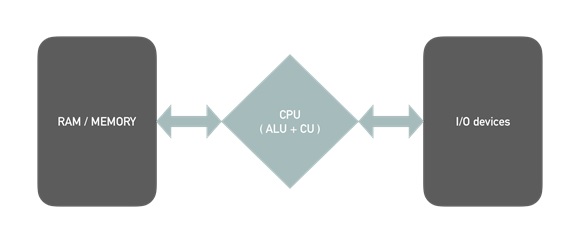
- CPU: MongoDB uses as many CPU’s as your server has. As of version > 3.X, it offers concurrence on document level. Operations handled on CPU are: page compression, data calculation, aggregation framework, map reduce, etc.
- RAM: Plan your server RAM sufficient to fit at least your indexes in memory. The best performance you’ll achieve is when and if your memory can fit both indexes and the working set of data for your application.
- I/O devices: It’s important to have a highly available application, thus plan to have a disk with higher IOPS coefficient. To measure DISK performance in terms of MongoDB application, use the mongoperf utility that comes in the default bundle of MongoDB executables.
#Tip 2: Use the Most Suitable Storage Engine
Starting with version 3.0, MongoDB came with a new storage engine called WiredTiger.
This engine uses document-level concurrency control for write operations. As a result, multiple clients can modify different documents of a collection at the same time.
Next to the document level concurrency control it uses MultiVersion Concurrency Control (MVCC). At the start of an operation, WiredTiger provides a point-in-time snapshot of the data to the transaction. A snapshot presents a consistent view of the in-memory data.
Last but not least, this engine uses a write-ahead transaction log in combination with checkpoints to ensure data durability.
#Tip 3: Setup Data Files Location
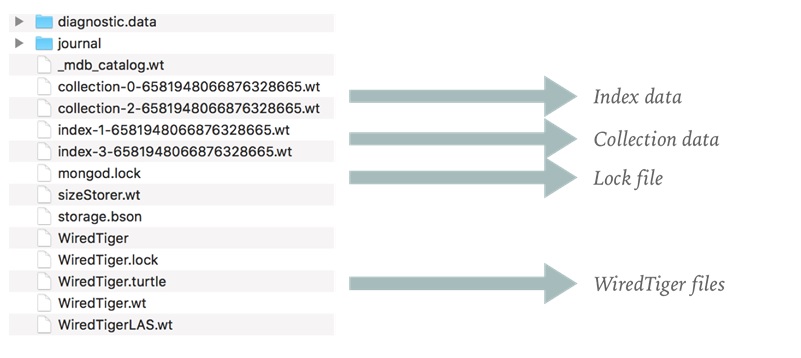
Default data directory structure
This behavior may be customized by using different parameters for MongoDB daemon startup.
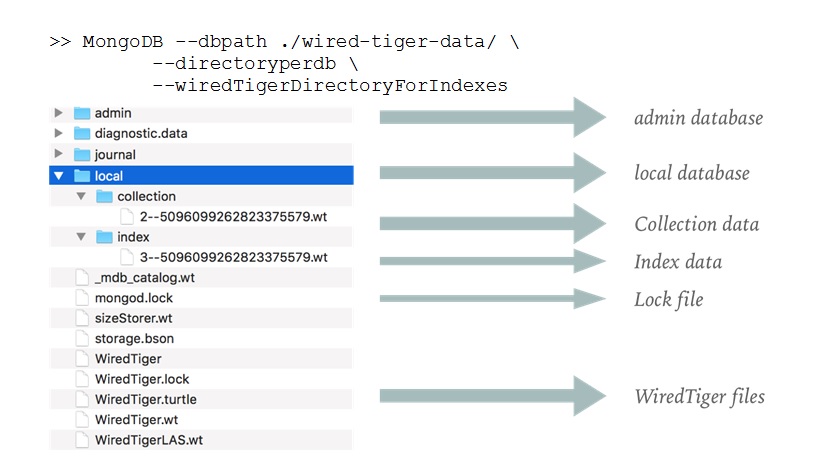
Directory per database and index files
Using the second method of MongoDB daemon startup, we force our server to save database and index files in separate directories. This strategy allows you to host files either on different partitions or even on different disks. This trick provides flexibility in choosing sufficient IOPS for the data you host.
#Tip 4: Setup Indexes
Having well-tuned hardware does not mean that your MongoDB is at peak performance.
It’s time to tune your data.
MongoDB comes with the following list of indexes: single field index, compound index, partial index, sparse index, text index and unique index. Each of these is suited for a specific range of search operations.
Please refer to the official MongoDB documentation for more detailed information on indexing.
#Tip 5: Identify the Most Optimal Query Plan and Use Hints
The MongoDB query optimizer processes queries and chooses the most efficient query plan for a query given the available indexes. The query system then uses this plan each time the query runs.
The following diagram illustrates how a query planner works.
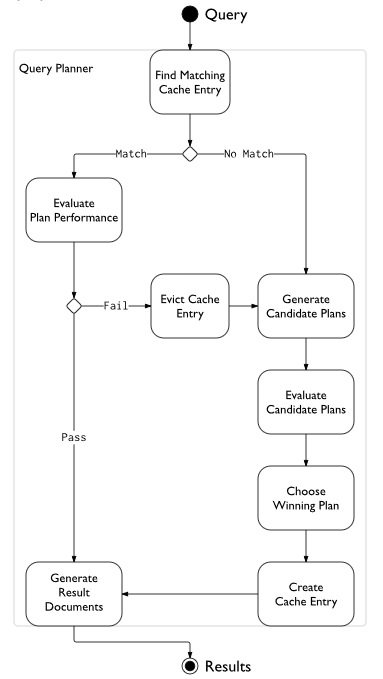
Use this command in MongoDB shell in order to identify what the winning plan is:
>> db.collectionName.find(…).explain()
The winning query plan is selected using a built-in empirical model. This is why a first query may run upon an index and the second time, the same query may use a different one (ex. your database data changes over time).
In order to direct the usage of a specific INDEX, use index hints:
>> db.collectionName.find({name: ‘val’}).hint({name: 1})
Be careful in your usage of hints, though – as there are very rare cases when explicit index hinting outperforms MongoDB’s query planner model.
#Tip 6: Equality | Sort | Range
There is a golden rule for index creation. As any performance component, an index in MongoDB database should be created from an application need. A need is usually a query that does 3 classical operations:
- Search over equality
- Search a value in range of values
- Sorts result set
So, index structure should be compliant with the following rule:
- Index prefix, first indexed fields should be equality fields
- Next to the equality, add to the index fields that will be used for sorting
- And the suffix of the index should be compound of the fields that do range operations.
#Tip 7: Covered Queries
A query can be called covered when:
- All the fields in the query are part of an index.
- All the fields returned in the query are in the same index.
Since all the fields present in the query are part of an index, MongoDB matches the query conditions and returns the result using the same index without actually looking inside the documents. Since indexes are present in RAM, fetching data from indexes is much faster as compared to fetching data by scanning documents.
In Conclusion
While there is no universal solution to all MongoDB performance issues, these tips will boost your overall application performance.
This list comes from my 7 years of personal experience of MongoDB usage. There are many other tips that may be applicable to your project not mentioned in this post and I’d love for you to share them in the comments!
Check out Pentalog’s events where we discuss about development, QA & devops topics.
Read this technical article that shows you step by step how to develop microservices in NodeJS.









